之前和别人讨论过森林图相关的东西,这两天摸鱼正好看到了一个非常有趣的新R包,能够比较快地画出好看的森林图,感觉相见恨晚,分享给大家~后面附了完整代码和工程文件
前言
Meta分析的常客
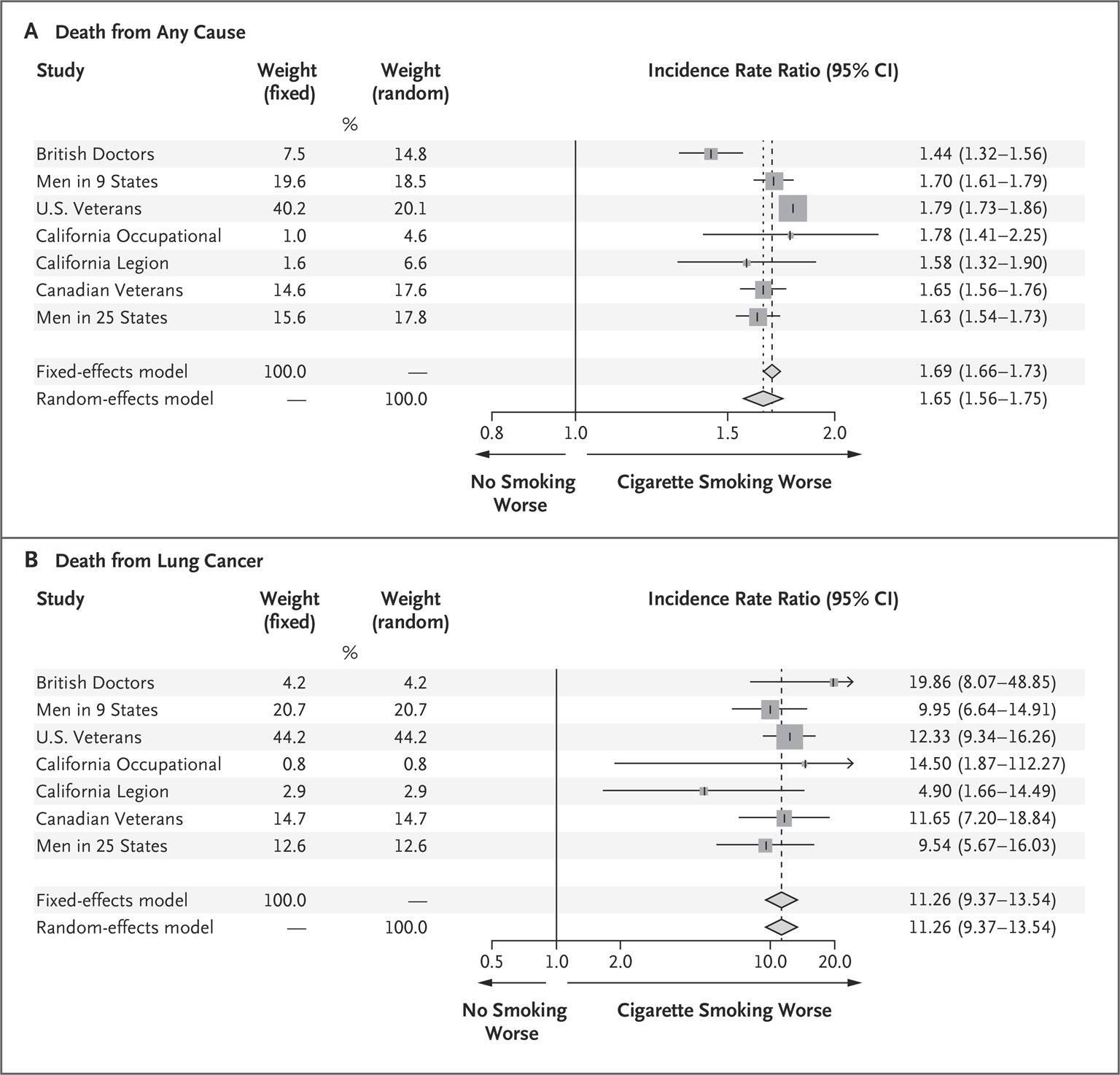
提到森林图(forest plot)大家肯定不会陌生,或多或少都见过,它在Meta分析中必不可少,能够简单直观展现汇总的结果。下图就是NEJM上一张比较典型的森林图。
Schumacher M., Rücker G., Schwarzer G. (2014) Meta-Analysis and the Surgeon General’s Report on Smoking and Health. New England Journal of Medicine 370:186-188. doi: 10.1056/NEJMc1315315
临床研究中的新应用
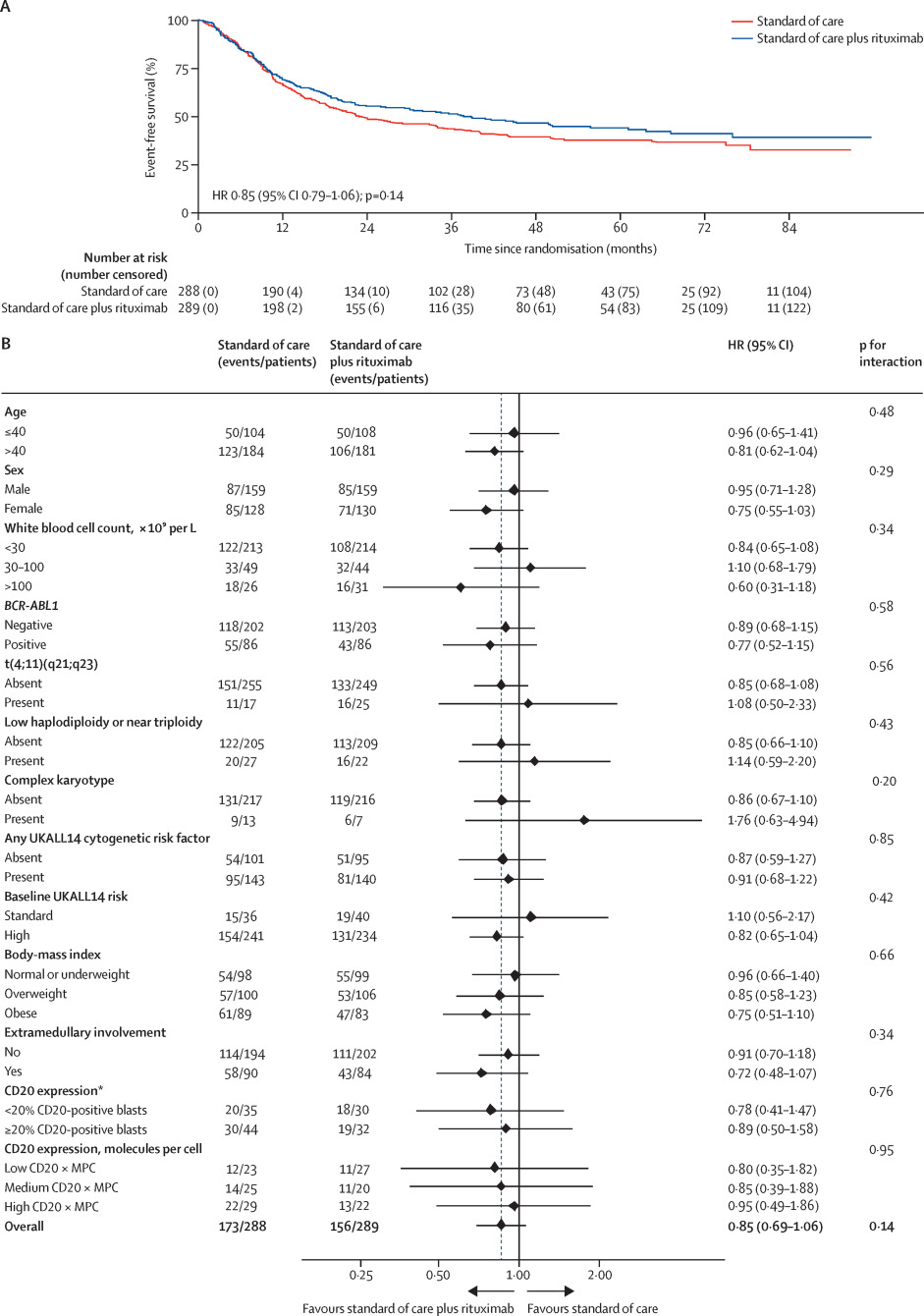
最近几年,在临床研究的论文中,它又用来作为亚组分析(Subgroup analysis)的展示(不同人群之间,如年龄,性别,疾病分期等亚组),其简洁美观受到了医学顶流期刊JAMA、BMJ、LANCET、NEJM的青睐,经常可以在各种RCT研究中看到。也有的研究在敏感性分析(Sensitivity analysis)的部分以森林图的形式呈现敏感性分析的结果(对缺失数据进行不同的填补方式,如末次结转,多重填补等)。例子太多了,柳叶刀官网随便打开篇文章就有森林图。
Marks D.I., Kirkwood A.A., Rowntree C.J., Aguiar M., Bailey K.E., Beaton B., et al. (2022) Addition of four doses of rituximab to standard induction chemotherapy in adult patients with precursor B-cell acute lymphoblastic leukaemia (UKALL14): a phase 3, multicentre, randomised controlled trial. The Lancet Haematology 9:e262-e275. doi: 10.1016/S2352-3026(22)00038-2
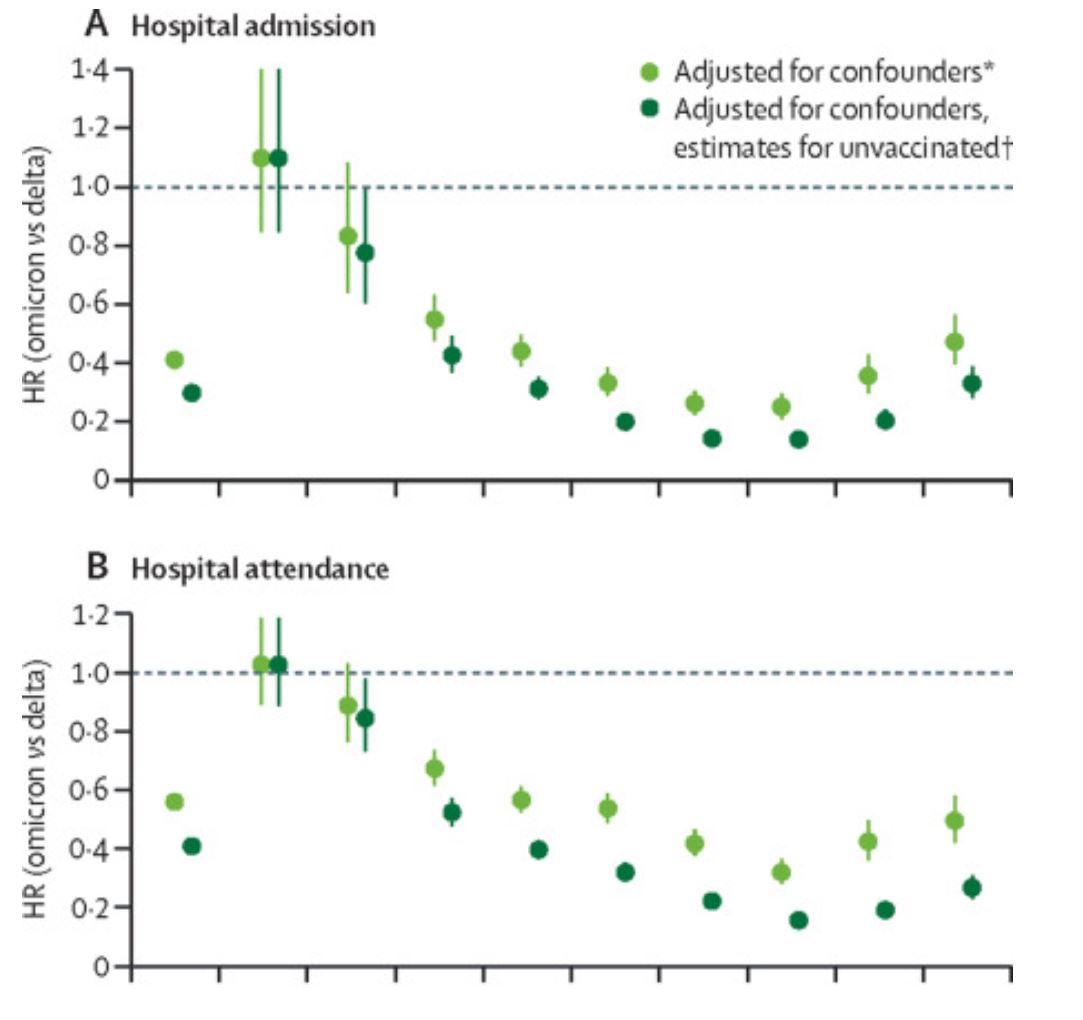
然后有时候也能看到这种比较花里胡哨的,它本质上也是森林图,就是旋转了一下
Nyberg T., Ferguson N.M., Nash S.G., Webster H.H., Flaxman S., Andrews N., et al. (2022) Comparative analysis of the risks of hospitalisation and death associated with SARS-CoV-2 omicron (B.1.1.529) and delta (B.1.617.2) variants in England: a cohort study. Lancet (London, England). doi: 10.1016/S0140-6736(22)00462-7
R语言代码及实战
简单介绍
之前我自己画森林图用的是forestplot包,它有个问题就是调整宽度挺不友好的,经常是R里面画好了以后还要拖到AI里做进一步美化,非常的麻烦,这次的新包很聪明的加了一列有宽度的空白区域,部分解决了这个问题。
R包作者是 Alim Dayim,他的Github首页 https://github.com/adayim,forestploter包的项目页 https://github.com/adayim/forestploter,项目页有详细的R包使用说明,本文代码基于作者简单修改。
完整文件代码
懒人可直接下载我的完整工程文件,点开直接跑就行,亲测可以运行 点击这里下载工程文件
准备工作
我的工作环境,R version 4.1.3,代码在RStudio中运行。
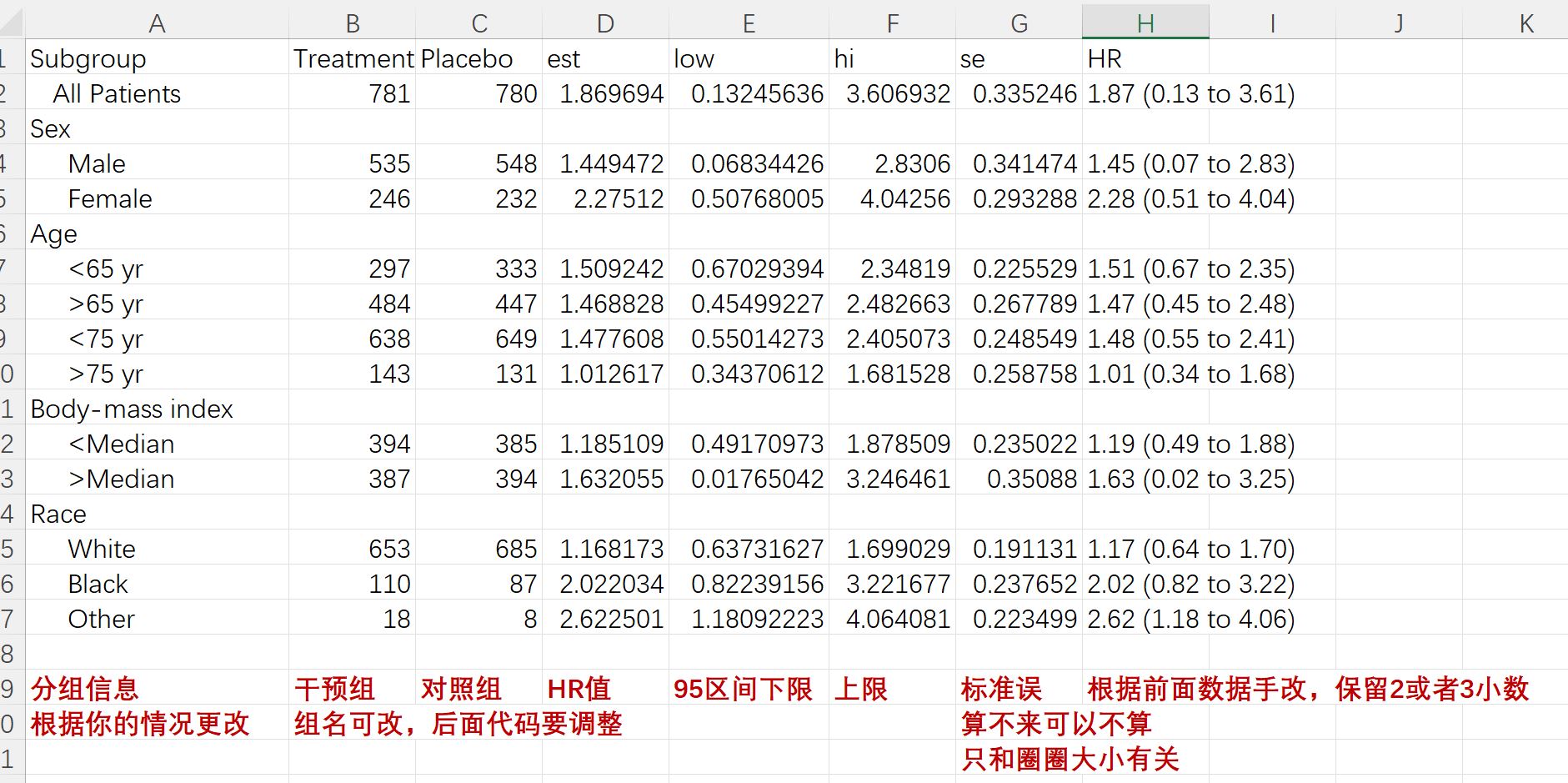
它提供的示例对没有R语言基础的人来说有点云里雾里,所以我简化了一下过程。点击这里,下载这个表格,用EXCEL打开,将你的数据按照以下Excel表格修改,然后还是保存为csv格式。
注意: 数据准备其实是最重要的,第一行列名更改一定要同步改代码,不然就跑不下去了
#设置一下镜像,不然国内网速下不动
options("repos"=c(CRAN="http://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
#安装R包
if(!require(forestploter))install.packages('forestploter',update = F,ask = F)
if(!require(grid))install.packages('grid',update = F,ask = F)
#读取刚刚保存的文件
data<-read.csv("mydata.csv")
#删除一些NA行,以及留空给森林图
data$Treatment <- ifelse(is.na(data$Treatment), "", data$Treatment) #如果改了列名,将Treatment修改
data$Placebo <- ifelse(is.na(data$Placebo), "", data$Placebo) #如果改了列名,将Placebo修改
data$` ` <- paste(rep(" ", 20), collapse = " ")
data$`HR (95% CI)` <-data$HR
绘图开始
首先设置一下参数,我把它有的一些参数都列举出来了,平时其实可以不用都设置,根据喜好即可
# 森林图参数
tm <- forest_theme(base_size = 10,#字符大小
ci_pch = 19,#森林图可信区间展示形状
ci_col = "blue",#森林图可信区间展示颜色
xaxis_lwd = 1.0,#横坐标宽度
refline_lwd = 2.0,#无效线宽度
refline_lty = "dashed",#无效线类型
refline_col = "red",#无效线颜色
footnote_cex = 0.6,#脚注字体大小
footnote_fontface = "italic",#脚注字体样式
footnote_col = "#636363")#脚注颜色
# 简单点的设置如下
tm <- forest_theme(base_size = 10,#字符大小
refline_col = "red",#无效线颜色
footnote_col = "blue")
#绘图时一定要根据自己数据情况调整参数,比如X轴范围和分割点,每个人的差异会比较大
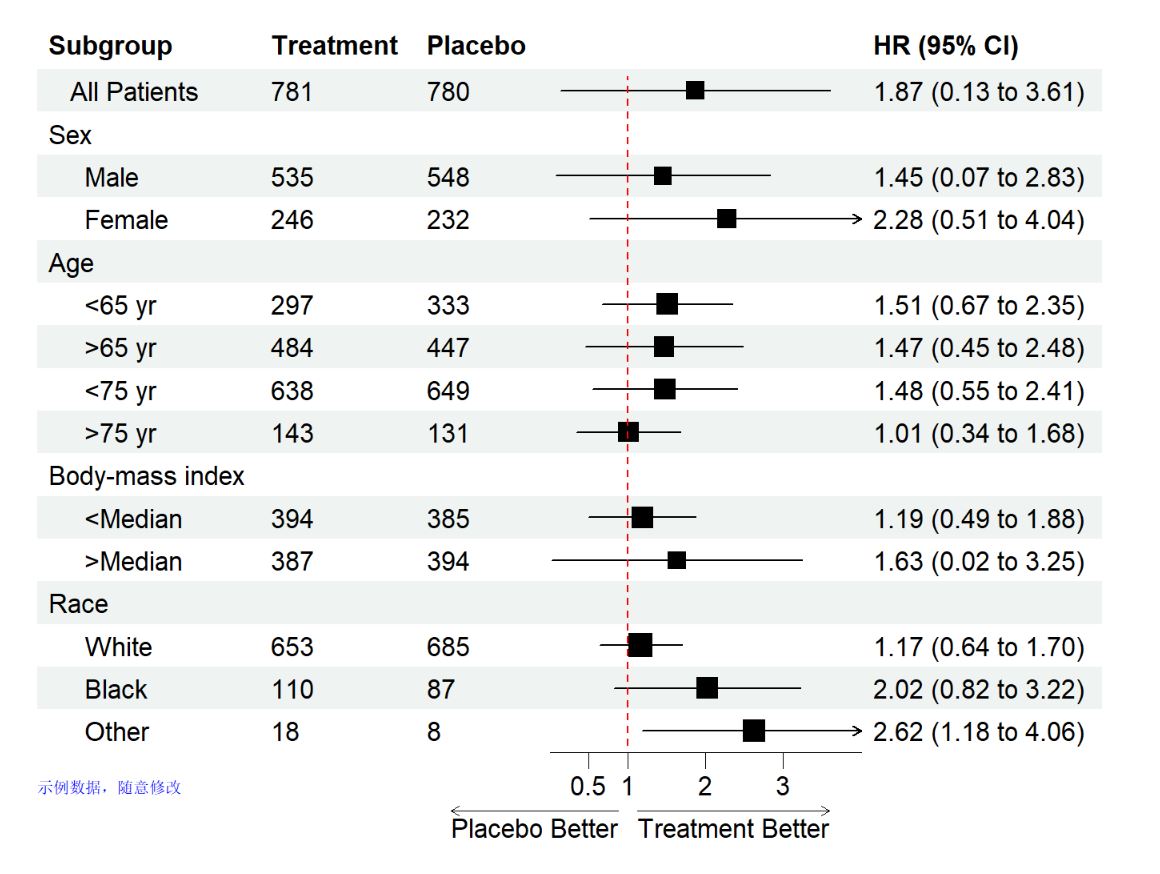
p <- forest(data[,c(1:3, 9:10)], #根据我们数据情况,展示的是1~3列和最后2列
est = data$est, #HR值
lower = data$low, #95%区间下限
upper = data$hi, #95%区间上限
sizes = data$se,#点估计框大小,用标准误映射
ci_column = 4,#可信区间在第几列展示
ref_line = 1,#X轴对应无效线,默认为1
arrow_lab = c("Placebo Better", "Treatment Better"),#箭头标签
xlim = c(0, 4),#X轴范围
ticks_at = c(0.5, 1, 2, 3),#设置X轴分割点
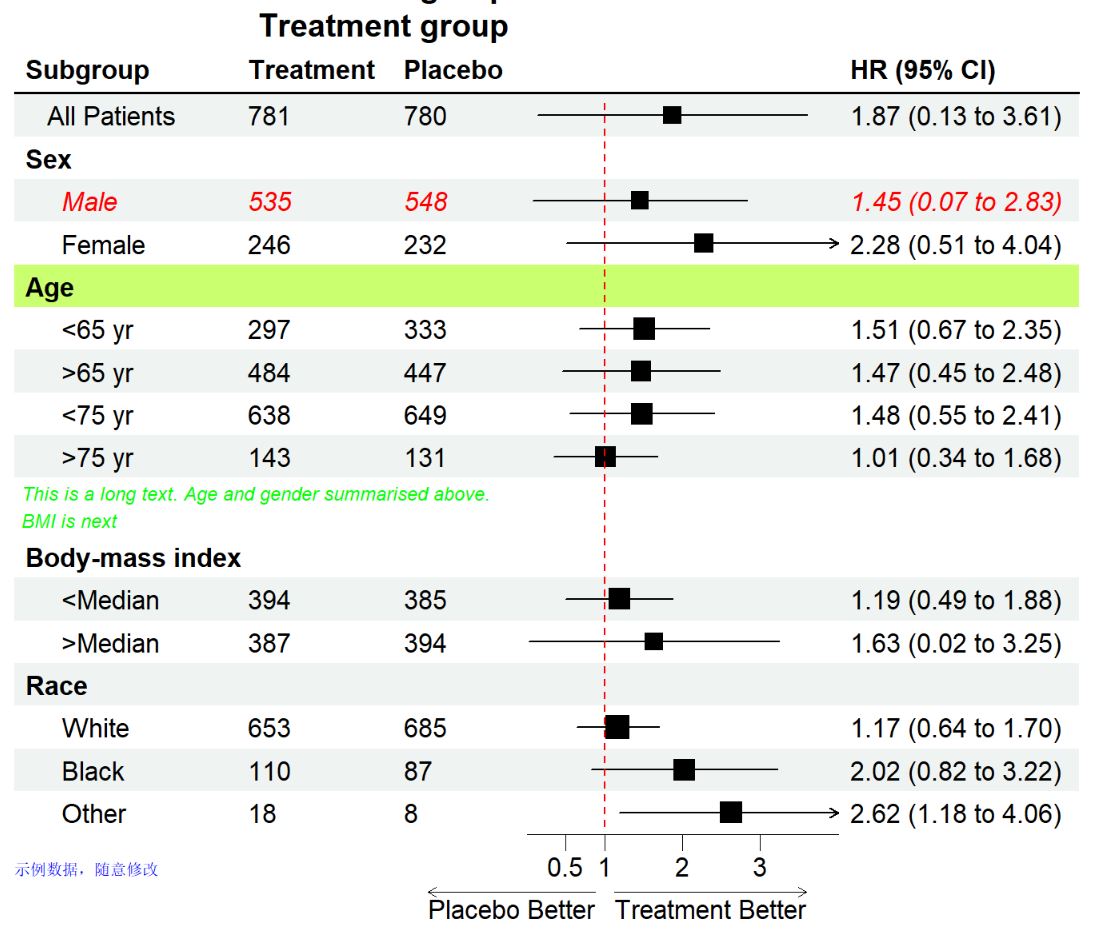
footnote = "示例数据,随意修改",#脚注内容
theme = tm)
#展示
plot(p)
#保存成PDF格式
pdf("forestplot.pdf",height = 8,width = 8)
p
dev.off()
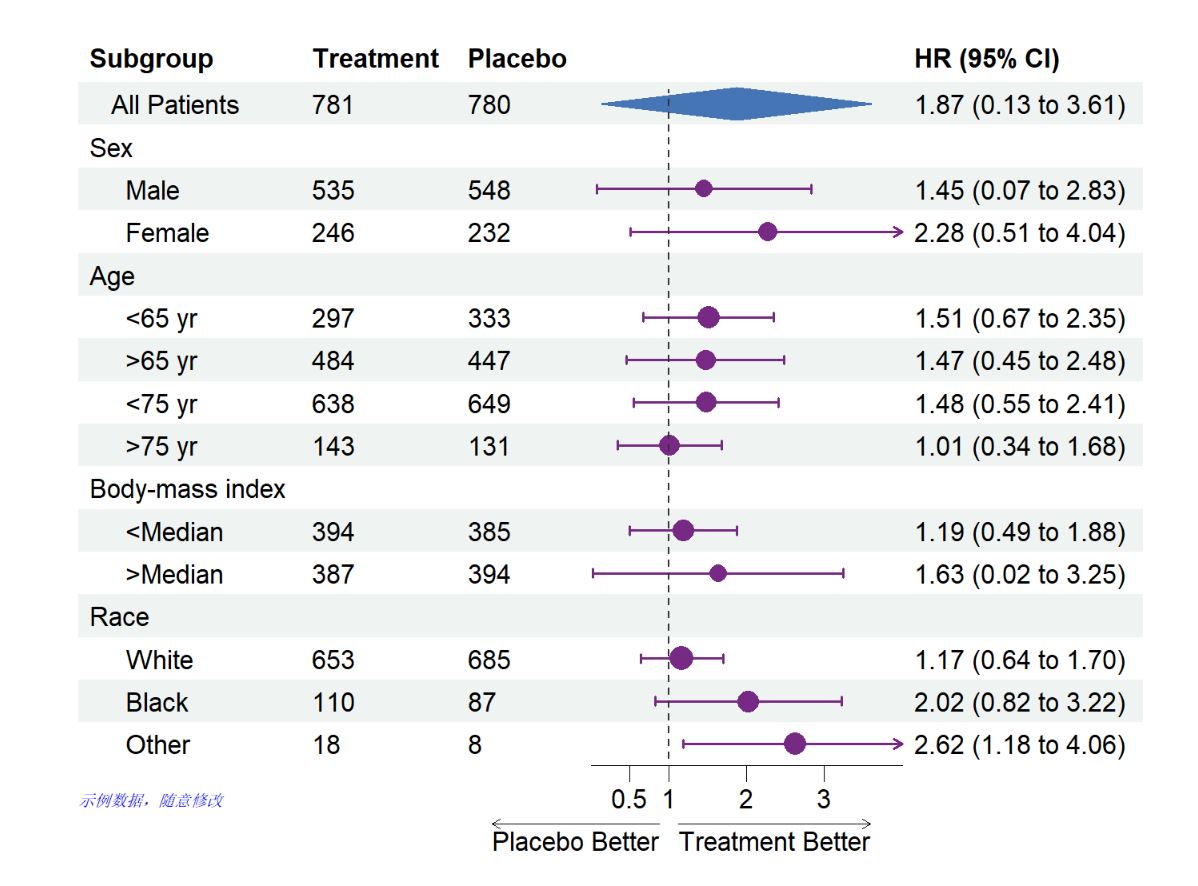
简单美化一下,汇总列突出显示
tm <- forest_theme(base_size = 10,
# 置信区间点形状,线类型/颜色/宽度
ci_pch = 16,
ci_col = "#762a83",
ci_lty = 1,
ci_lwd = 1.5,
ci_Theight = 0.2, # Set an T end at the end of CI
# 参考线宽/类型/颜色
refline_lwd = 1,
refline_lty = "dashed",
refline_col = "grey20",
# 垂直的线宽/类型/颜色
vertline_lwd = 1,
vertline_lty = "dashed",
vertline_col = "grey20",
# 填充和边框的摘要颜色
summary_fill = "#4575b4",
summary_col = "#4575b4",
# 脚注
footnote_cex = 0.6,
footnote_fontface = "italic",
footnote_col = "blue")
p <- forest(data[,c(1:3, 9:10)], #根据我们数据情况,展示的是1~3列和最后2列
est = data$est, #HR值
lower = data$low, #95%区间下限
upper = data$hi, #95%区间上限
sizes = data$se,#点估计框大小,用标准误映射
is_summary = c(TRUE,rep(FALSE, nrow(data)-1)), #这里是为了突出第一行菱形汇总
ci_column = 4,#可信区间在第几列展示
ref_line = 1,#X轴对应无效线,默认为1
arrow_lab = c("Placebo Better", "Treatment Better"),#箭头标签
xlim = c(0, 4),#X轴范围
ticks_at = c(0.5, 1, 2, 3),#设置X轴分割点
footnote = "示例数据,随意修改",#脚注内容
theme = tm)
plot(p)
这个R包还提供了一些编辑调整,全部加上效果如下。根据自己选择修改,也可以导出到AI里进一步调整,看个人习惯。
# 编辑第3行,设置为红色,斜体
g <- edit_plot(p, row = 3, gp = gpar(col = "red", fontface = "italic"))
# 分组信息加粗,需要根据自己数据行号调整
g <- edit_plot(g,
row = c(2, 5, 10, 13, 17, 20),
gp = gpar(fontface = "bold"))
# 加大标题
g <- insert_text(g,
text = "Treatment group",
col = 2:3,
part = "header",
gp = gpar(fontface = "bold"))
# 表头下面加下划线
g <- add_underline(g, part = "header")
# 将第五行的背景色整成绿色的
g <- edit_plot(g, row = 5, which = "background",
gp = gpar(fill = "darkolivegreen1"))
# 第10行直接加入文字
g <- insert_text(g,
text = "This is a long text. Age and gender summarised above.\nBMI is next",
row = 10,
just = "left",
gp = gpar(cex = 0.6, col = "green", fontface = "italic"))
plot(g)